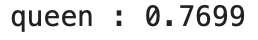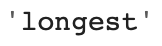### 라이브러리 호출 및 데이터셋 로딩
import numpy as np
%matplotlib notebook
import matplotlib.pyplot as plt
plt.style.use('ggplot')
from sklearn.decomposition import PCA
from gensim.test.utils import datapath, get_tmpfile
from gensim.models import KeyedVectors
from gensim.scripts.glove2word2vec import glove2word2vec
glove_file = datapath('/content/drive/MyDrive/glove.6B.100d.txt')
word2vec_glove_file = get_tmpfile("glove.6B.100d.word2vec.txt") # 글로브 데이터를 워드투벡터 형태로 변환
glove2word2vec(glove_file, word2vec_glove_file)
### glove2word2vec의 파라미터
glove_file: 글로브 입력 파일
word2vec_glove_file: 워드투벡터 출력 파일
라이브러리 호출 및 데이터셋 로딩 결과
### 'bill'과 유사한 단어의 리스트를 반환
model = KeyedVectors.load_word2vec_format(word2vec_glove_file) # 파이썬 콘솔에서 결과를 확인하기 위해 word2vec_glove_file 파일을 로딩
model.most_similar('bill') # 단어(bill) 기준으로 가장 유사한 단어들의 리스트를 보여줌
'bill'과 유사한 단어의 리스트 반환 결과
### 'cherry'와 유사한 단어의 리스트를 반환
model.most_similar('cherry') # 단어(cherry) 기준으로 가장 유사한 단어들의 리스트를 보여줌
'cherry'와 유사한 단어의 리스트 반환 결과
### 'cherry'와 관련성이 없는 단어의 리스트를 반환
model.most_similar(negative=['cherry']) # 단어(cherry)와 관련성이 없는 단어들을 추출
'cherry'와 관련성이 없는 단어의 리스트 반환 결과
### 'woman','king'과 유사성이 높으면서 'man'과 관련성이 없는 단어를 반환
result = model.most_similar(positive=['woman','king'], negative=['man']) # woman,king과 유사성이 높으면서 man과 관련성이 없는 단어를 반환
print("{} : {:.4f}".format(*result[0]))
단어 간 긍정, 부정 관련성을 고려하여 queen의 결과를 출력
### 'austalia','beer','france'와 관련성이 있는 단어를 반환
def analogy(x1,x2,y1):
result = model.most_similar(positive=[y1,x2],negative=[x1])
return result[0][0]
analogy('australia','beer','france')
### 'tall','tallest','long' 단어를 기반으로 새로운 단어를 유추
analogy('tall','tallest','long')
새로운 단어를 유추한 결과
### 'breakfast cereal dinner lunch'중 유사도가 낮은 단어를 반환
print(model.doesnt_match("breakfast cereal dinner lunch".split())) # 유사도가 가장 낮은 단어를 반환