
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 클러스터링
- 코랩
- NLTK
- 과적합
- 양방향 RNN
- 성능 최적화
- 임베딩
- RNN
- KONLPY
- 텍스트 마이닝
- 합성곱층
- 망각 게이트
- 코딩테스트
- 이미지 분류
- cnn
- 생성모델
- 순환 신경망
- 풀링층
- 시계열 분석
- 입력층
- 합성곱 신경망
- 딥러닝
- 프로그래머스
- 전이학습
- 자연어 전처리
- 카운트 벡터
- 원-핫 인코딩
- 출력층
- 완전연결층
- COLAB
Archives
- Today
- Total
Colab으로 하루에 하나씩 딥러닝
자연어 전처리_3.임베딩_3) 예측 기반 임베딩 본문
728x90
예측 기반 임베딩
- 신경망 구조 혹은 모델을 이용하여 특정 문맥에서 어떤 단어가 나올지 예측하면서 단어를 벡터로 만드는 방식
- 대표적으로 워드투벡터가 있음
워드투벡터(Word2Vec)
- 신경망 알고리즘으로 주어진 텍스트에서 텍스트의 각 단어마다 하나씩 일련의 벡터를 출력함
- 코사인 유사도를 이용하여 특정 단어의 동의어를 찾을 수 있음
- 수행 과정
- 일정한 크기의 윈도우로 분할된 텍스트를 신경망 입력으로 사용
- 모든 분할된 텍스트는 한 쌍의 대상 단어와 컨텍스트로 네트워크에 공급
- 네트워크의 은닉층에는 각 단어에 대한 가중치가 포함 됨
더보기
<데이터 셋 가져오기>
아래의 코드 중 peter.txt는 피터팬 무료 이북 텍스트를 참조하였습니다.
### 데이터셋을 메모리로 로딩하고 토큰화 적용
import nltk
nltk.download('punkt')
from nltk.tokenize import sent_tokenize, word_tokenize
import warnings
warnings.filterwarnings(action='ignore')
import gensim
from gensim.models import Word2Vec
sample = open("/content/drive/MyDrive/peter.txt", "r", encoding="UTF-8") # 피터펜 데이터셋 로딩
s = sample.read()
f = s.replace("\n"," ") # 줄바꿈(\n)을 공백(" ")으로 변환
data = []
for i in sent_tokenize(f): # 로딩한 파일의 각 문장마다 반복
temp = []
for j in word_tokenize(i): # 문장을 단어로 토큰화
temp.append(j.lower()) # 토큰화된 단어를 소문자로 변환하여 temp에 저장
data.append(temp)
data
CBOW(Continuous Bag Of Words)
- 단어를 여러 개 나열한 후 이와 관련된 단어를 추정하는 방식
- 문장에서 등장하는 n개의 단어 열에서 다음에 등장할 단어를 예측함
### 데이터셋어 CBOW 적용 후 'peter'와 'wendy'의 유사성 확인
model1 = gensim.models.Word2Vec(data, min_count=1, size=100, window=5, sg=0)
print("Cosine similarity between 'peter' " + "'wendy' - CBOW : ", model1.similarity('peter','wendy')) # 결과 출력
※ 워드투벡터는 무작위로 초기화되고, 훈련 과정에서도 무작위 처리되기 때문에 결과가 위와 다를 수 있음
### Word2Vec의 파라미터
data: CBOW를 적용할 데이터셋
min_count: 단어에 대한 최소 빈도수 제한(빈도가 적은 단어들은 학습하지 않음)
size: 워드 벡터의 특징 값. 임베딩된 벡터의 차원
window: 컨텍스트 윈도우 크기
sg: 0일 때는 CBOW를 의미, 1일 때는 skip-gram을 나타냄### 'peter'와 'hook'의 유사성 확인
print("Cosine similarity between 'peter' " + "'hook' - CBOW : ",
model1.similarity('peter','hook'))
skip-gram
- CBOW와 반대로 특정한 단어에서 문맥이 될 수 있는 단어를 예측함
- 중심 단어에서 주변 단어를 예측하는 방식을 사용
### 데이터셋에 skip-gram 적용 후 'peter'와 'wendy'의 유사성 확인
model2 = gensim.models.Word2Vec(data, min_count=1, size=100,
window=5, sg=1) # skip-gram 모델 생성
print("Cosine similarity between 'peter' " +
"'wendy' - Skip Gram : ",
model2.similarity('peter','wendy')) # 결과 출력
### 'peter'와 'hook'의 유사성
print("Cosine similarity between 'peter' " + "'hook' - Skip Gram : ",
model2.similarity('peter', 'hook'))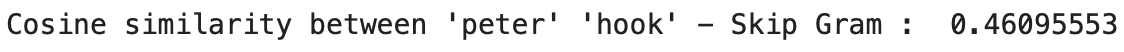
참고: 출처: 서지영, 『딥러닝 텐서플로 교과서』, 길벗(2022)
'딥러닝_개념' 카테고리의 다른 글
| 자연어 전처리_3.임베딩_5) 한국어 임베딩 (0) | 2022.12.16 |
|---|---|
| 자연어 전처리_3.임베딩_4) 횟수/예측 기반 임베딩 (1) | 2022.12.15 |
| 자연어 전처리_3.임베딩_2) 횟수 기반 임베딩 (0) | 2022.12.13 |
| 자연어 전처리_3.임베딩_1) 희소 표현 기반 임베딩(원-핫 인코딩) (0) | 2022.12.12 |
| 자연어 전처리_2.전처리_4) 정규화 (1) | 2022.12.10 |
'딥러닝_개념' Related Articles
more



