
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
Tags
- 코랩
- 전이학습
- 원-핫 인코딩
- KONLPY
- 클러스터링
- 입력층
- 프로그래머스
- 출력층
- COLAB
- 망각 게이트
- RNN
- 자연어 전처리
- 완전연결층
- 카운트 벡터
- 이미지 분류
- 성능 최적화
- 순환 신경망
- 풀링층
- 딥러닝
- 합성곱 신경망
- cnn
- 양방향 RNN
- 텍스트 마이닝
- 시계열 분석
- 합성곱층
- 과적합
- 임베딩
- NLTK
- 생성모델
- 코딩테스트
Archives
- Today
- Total
Colab으로 하루에 하나씩 딥러닝
클러스터링_1.K-평균 군집화 본문
728x90
K-평균 군집화(K-Means)
- 데이터를 입력받아 소수의 그룹으로 묶는 알고리즘
- 레이블이 없는 데이터를 입력받아 각 데이터에 레이블을 할당해서 군집화를 수행
- 데이터가 비선형일 때, 군집 크기가 다를 때, 군집마다 밀집도와 거리가 다를 때 사용할 경우 데이터 분류가 원하는 결과와 다르게 발생할 수 있음
K-Means 원리
1. 중심점 선택
- 클러스터 중심인 중심점을 구하기 위해 임의의 점 K를 선택
2. 클러스터 할당
- 각 중심에 대한 거리를 계산하여 각 데이터를 가장 가까운 클러스터에 할당
3. 새로운 중심점 선택
- 할당된 데이터 평균을 계산하여 새로운 클러스터 중심을 결정
4. 범위 확인
- 클러스터 할당이 변경되지 않을 때까지 2~3을 반복
K-Means 실습
### 라이브러리 호출
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
import cv2
import os, glob, shutil### GPU 확인(권장 사항)
gpus = tf.config.experimental.list_physical_devices('GPU')
if gpus:
try:
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
logical_gpus = tf.config.experimental.list_logical_devices('GPU')
print(len(gpus), "Physical GPUs", len(logical_gpus), "Logical GPUs")
except RuntimeError as e:
print(e)
### git 클론을 통한 필요 데이터셋 로드
!git clone https://github.com/gilbutITbook/080263.git
### 데이터셋 준비
input_dir = '/content/080263/chap11/data/pets'
glob_dir = input_dir + '/*.jpg'
images = [cv2.resize(cv2.imread(file), (224,224)) for file in glob.glob(glob_dir)]
paths = [file for file in glob.glob(glob_dir)]
images = np.array(np.float32(images).reshape(len(images),-1)/255)### 특성 추출
model = tf.keras.applications.MobileNetV2(include_top=False, weights='imagenet',
input_shape=(224,224,3)) # 설명 1
predictions = model.predict(images.reshape(-1,224,224,3)) # 설명 2
pred_images = predictions.reshape(images.shape[0], -1)
상세 설명
- 특성 추출을 위해 빠르고 코드 길이가 길지 않은 MobileNetV2 모델 사용
- include_top=False: 네트워크 최상단에 완전연결층을 넣을지 여부, False이므로 완전연결층을 추가하지 않음
- weights='imagenet': 'imagenet', 'None'으로 선택 가능
- imagenet: ImageNet으로 사전 훈련된 가중치 사용
- None: 임의의 초깃값을 설정
- input_shape=(224,224,3): 입력의 크기를 의미, 224 × 224 크기이며, 3은 RGB를 나타냄
### 클러스터링 구성
k = 2
kmodel = KMeans(n_clusters=k, random_state=728)
kmodel.fit(pred_images)
kpredictions = kmodel.predict(pred_images)
!mkdir -p data/output
shutil.rmtree('/content/data/output')
for i in range(k):
os.makedirs('/content/data/output' + str(i))
for i in range(len(paths)):
shutil.copy2(paths[i],'/content/data/output' + str(kpredictions[i]))
### KMeans에서 클래스 개수 알아보기
sil = []
kl = []
kmax = 10
for k in range(2, kmax+1):
kmeans2 = KMeans(n_clusters=k).fit(pred_images)
labels = kmeans2.labels_
sil.append(silhouette_score(pred_images, labels, metric='euclidean'))
kl.append(k)### 실루엣의 시각화
plt.plot(kl, sil)
plt.ylabel('Silhoutte Score')
plt.ylabel('K')
plt.show()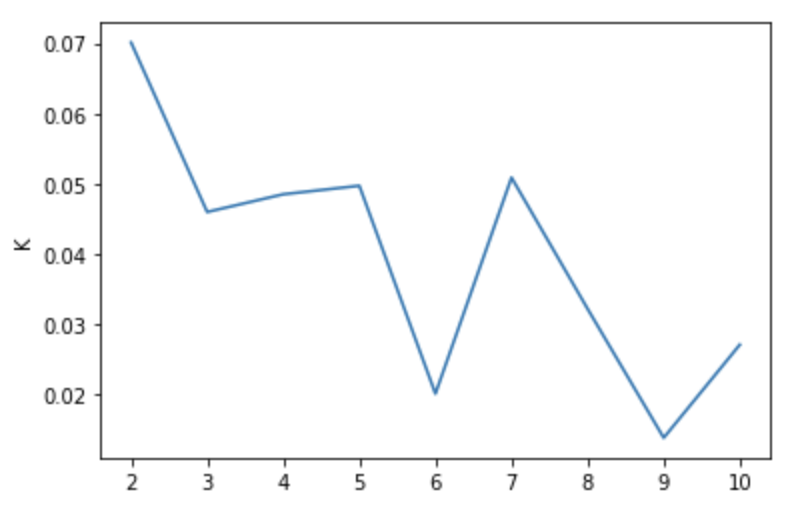
참고: 서지영, 『딥러닝 텐서플로 교과서』, 길벗(2022)
'딥러닝_개념' 카테고리의 다른 글
| 클러스터링_3.자기 조직화 지도 (0) | 2023.01.31 |
|---|---|
| 클러스터링_2.가우시안 혼합 모델 (0) | 2023.01.30 |
| 성능 최적화_3.조기 종료를 통한 최적화 (0) | 2023.01.26 |
| 성능 최적화_2.드롭아웃을 통한 최적화 (0) | 2023.01.25 |
| 성능 최적화_1.배치 정규화를 통한 최적화 (0) | 2023.01.21 |
'딥러닝_개념' Related Articles
more



